
Delaying Asynchronous Message Processing
At Indeed, we always consider what’s best for the job seeker. When a job seeker applies for a job, we want them to have every opportunity to be hired. It is unacceptable for a job seeker to miss an employment opportunity because their application was waiting to be processed while the employer makes a hire. The team responsible for handling applies to jobs posted on Indeed maintains service level objectives (SLOs) for application processing time. We constantly consider better solutions for processing applications and scaling this system.
Indeed first adopted RabbitMQ within our aggregation engine to handle the volume of jobs we process daily. With this success, we integrated RabbitMQ into other systems, such as our job seeker application processing pipeline. Today, this pipeline is responsible for processing more than 1.5 million applications a day. Over time, the team needed to implement several resilience patterns around this integration including:
- Tracing messages from production to consumption
- Delaying message processing when expected errors occur
- Sending messages that cannot be processed completely to a dead letter queue
Implementing a delay queue
A delay queue prolongs message processing by setting a message aside for a set amount of time. To understand why we implemented this pattern, consider several key behaviors of most messaging systems. RabbitMQ:
- Guarantees at least once delivery (some messages can be delivered multiple times)
- Allows acknowledgement (ack), negative acknowledgement (nack), or requeue of messages
- Requeues messages to the head of the queue, not the end
The team implemented a delay queue primarily to deal with the third item. Since RabbitMQ requeues messages to the head of the queue, the next message your consumer will likely process is the one that just failed. Although this is a non-issue for a small volume of messages, critical problems occur as the number of unprocessable messages exceeds the number of consumer threads. Since consumers can’t get past the group of unprocessable messages at the beginning of the queue, messages back up within the cluster.
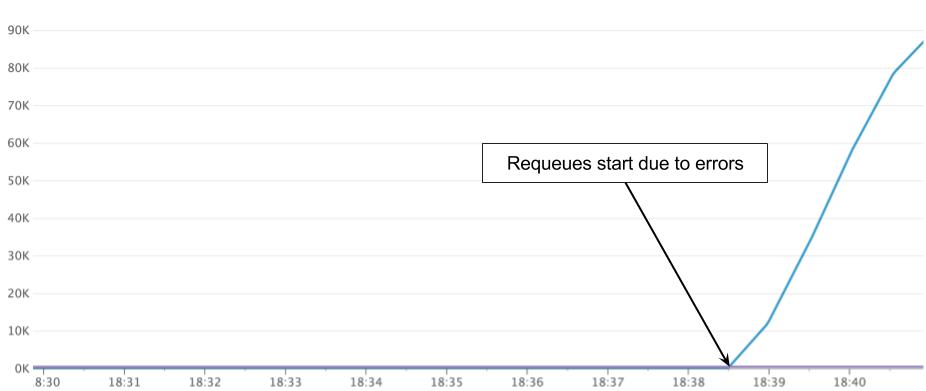
Figure 1. Message backup within the cluster
How it works
While mechanisms such as a dead letter queue allowed us to delay message processing, they often required manual intervention to return a system to a healthy state. The delay queue pattern allows our systems to continue processing. Additionally, it requires less work from our first responders (engineers who are “on call” during business hours to handle production issues), Site Reliability Engineers (SREs), and our operations team. The following diagram shows the options for a consumer process that encounters an error:
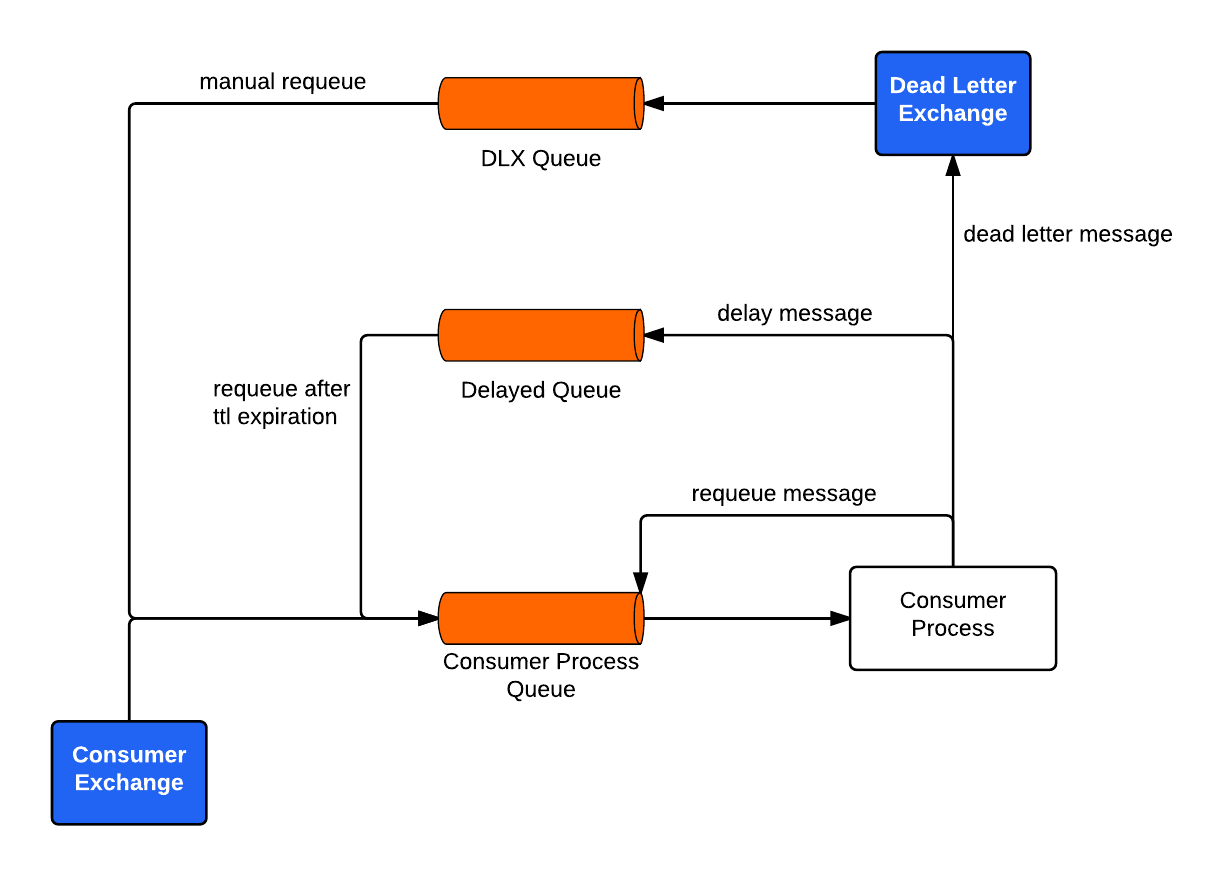
Figure 2. Asynchronous message consuming system
When a consumer encounters an error and cannot process a message, engineers must choose to have the consumer requeue, place into the delayed queue, or deliver to the dead letter queue. They can make this decision by considering the following questions:
Was the error unexpected?
If your system encounters an unexpected error that is unlikely to happen again, requeue the message. This gives your system a second chance to process the message. Requeuing the message is useful when you encounter:
- Network blips in service communication
- A database operation failure caused by a transaction rollback or the inability to obtain a lock
Does the dependent system need time to catch up?
If your system encounters an expected error that may require a little time before reprocessing, delay the message. This allows downstream systems to catch up so the next time you try to process the message, it’s more likely to succeed. Delaying the message is useful for handling:
- Database replication lag issues
- Consistency issues when working with eventually consistent systems
Would you consider the message unprocessable?
If a message is unprocessable, send it to your dead letter queue. An engineer can then inspect the message and investigate before dropping or manually requeueing it. A dead letter queue is useful when your system:
- Expects a message to contain information that is missing
- Requires manual inspection of dependent resources before trying to reprocess the message
Escalation policy
To further increase your system’s resilience, you might establish an escalation policy among the three options. If a system requests a message to be requeued n times, start to delay the message. If the message is delayed another m times, send it to your dead letter queue. That’s what we have done.
This type of policy has reduced the work for our first responders, SREs, and operations team. We have been able to scale our application processing system as we process more and more candidate applications every day.