I used to highlight this project in my resumé, but I’ve found that it doesn’t really fit the format of a traditional resumé very well. While it’s definitely an accomplishment, it’s very narrative driven and requires more context than a single page.
In early 2016, I was working from home and caring for my child while we waited for them to be able to attend daycare. Shortly after returning to the office, I found myself in one of our tech leads meetings. We were discussing the need to upgrade Spring 3 to Spring 4, as well as Java 7 to Java 8. Each of these were a fairly sizable project on their own, and so I had decided to volunteer for the Spring 4 upgrade while a colleague of mine took on the Java 8 effort.
In this post, I explain how I went about tackling the project, the tooling I implemented along the way, and how automation allowed me to kick back, relax, enjoy some lattes, and play some pool (billiards).
Some important context
It’s important to note that I cannot speak for Indeed’s current library version management solution, and it’s very likely to have changed since my time there as it was an active point of discussion in the Java guild.
Indeed had an interesting approach to software library version management. On one hand, it made things really easy to automatically upgrade every week. On the other, it often left people confused as to why they couldn’t use newer versions of libraries while other parts of the company lagged behind (this was effectively the slowest common denominator, the last hold out, etc). Major version upgrades of core libraries were done all at once, across the entire company. This usually required extensive knowledge of the various subsystems, and expertise on how to run and debug the system accordingly. Few people at the company were able to perform such a task.
I cannot speak to why things were done this way, only that it was the environment we were working in.
Problem 1: Identifying impacted projects
At the time, code search was OK. Atlassian Fisheye was the search tool of choice, but our deployment was unreliable. It wouldn’t be until a year or so later that Sourcegraph really starts to take off. With some creative thinking and a nights worth of work, I built the initial version of a system to ONLY index our dependency graph. Internally, I named this service Darwin, after Charles Darwin, as it was intended to help evolve Indeeds’ software ecosystem. By indexing just our dependency graph, we could easily identify how the different systems relate to one another using common graph traversal algorithms.
This service exposed a few different endpoints, but the one that was used the most returned a topological ordering of dependencies given a “root” (for instance, Spring 3’s core library). This made it easy to build automation and larger reports to help inform the company about the potential impact and progress.
Using this tool, I was able to identify more than 800 repositories that were within the scope of the upgrade (less than half of all repositories at the company). We were also able to identify other, third-party libraries that were not initially in scope that needed to get upgraded along in that process.
Problem 2: Identifying notable changes and their impact
Cool… so we know what the possible scope is, but we don’t really have a great handle on what’s actually changing. Reading the changelog is a great start to get insight into noteworthy changes, but it won’t always capture the ones that impact your projects.
While major library versions often include breaking changes, intuition suggested that for the majority of use cases, there will be few changes required to upgrade a library version (especially for an established project like Spring). It’s the more complex or edge use cases that often need more modifications and attention. So, before diving into any automation, I wanted to find a way to surface differences between the two versions of the library that we were moving to.
With a fair amount of research, I came across the Java API Compliance Checker project. This command line tool worked by taking two Java JARs of the same library, but different versions and compared their interfaces. This made it easy to see just how different the two libraries are from an API perspective, and from an ABI perspective (application binary interface).
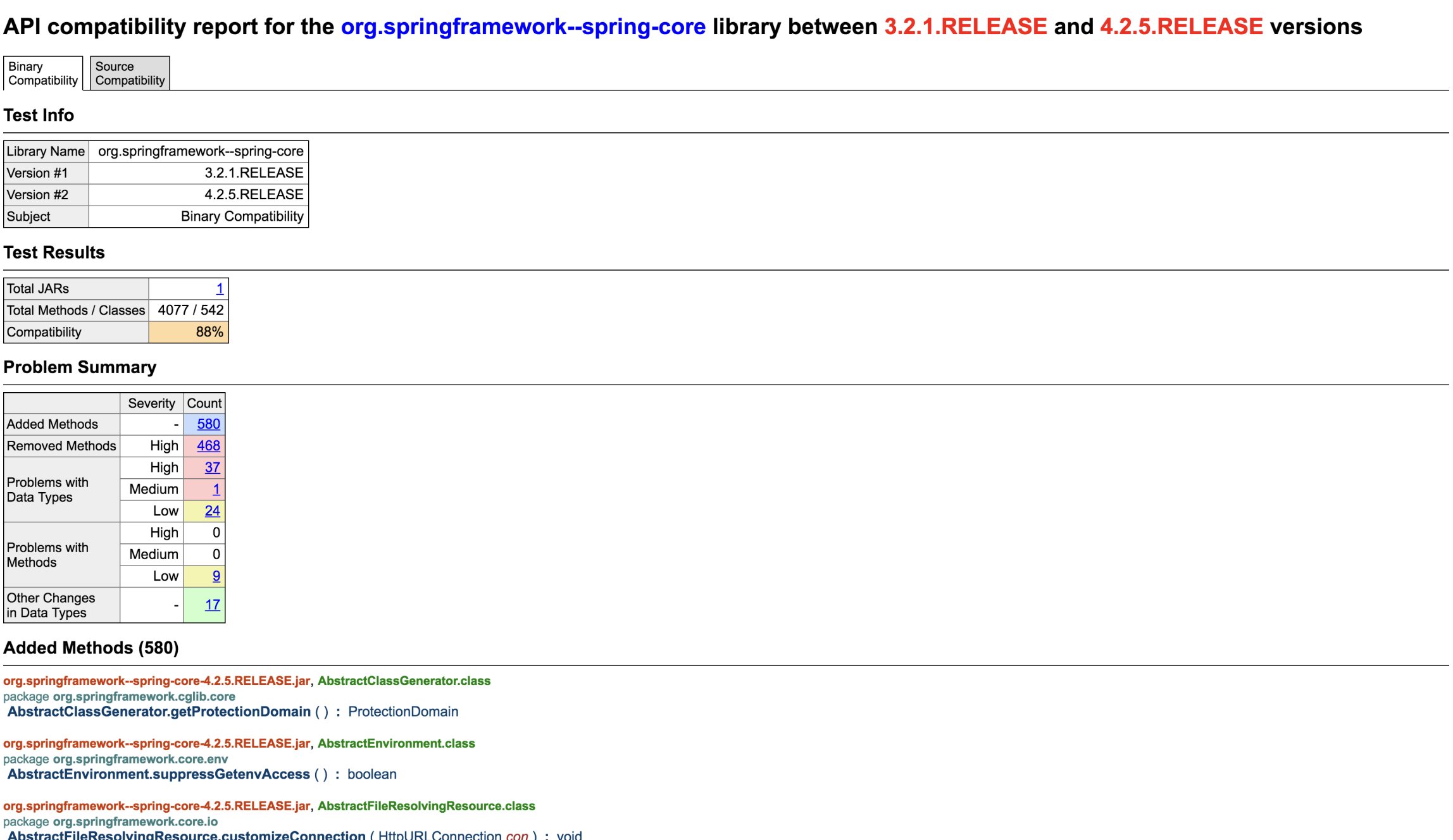
Figure 1: Example report showing high level differences between two versions of a library.
As I dug further into the report, it surfaced more specific details about how things changed. This made it much easier to know which breaking changes we needed to be on the lookout for when upgrading, and in some cases we could write a patch for the change from the description alone.

Figure 2: Example report showing high level differences between two versions of a library.
Image courtesy of Guava Google group discussion
One thing that I really liked about this tool was that once you had a delta of the versions, you could create a compatibility report that outlined if and how changes in the library would impact systems that consumed that library. Using my newly developed API and a little scripting, I was able to automatically run a compatibility report for every system at Indeed downstream of the Spring 3 core libraries.
Add in a little XML parsing and the generation of an aggregated index.html view, and we could easily see which systems
were going to be impacted the most. Each cell linked to their associated report and were color coded based on the result
of their compatibility report. Green meant the upgrade was compatible and no code changes were required. Yellow meant
some changes may be required based on usage. Finally, red meant that additional work needed to be done to the system.
Figure 3: The aggregated index.html view.
Problem 3: Automating changes
Now that we knew the scope of affected projects and which required more attention, we needed a way to patch, compile,
test, and submit pull requests for all 800+ repositories. In addition to that, libraries needed to be published to a
local artifact cache, so they could be resolved by subsequent builds (kind of like npm links but for jar files).
To perform the automation, I decided to use NodeJS. I wanted a language that was fairly accessible to anyone at the
company, and it was hard to turn down the number of pre-built libraries that were available. Promises, async, and
await made it really easy to reason about the code flow and the single threaded nature of JavaScript made it easy to
understand what was going on at any point in time.
The client logic was relatively straight forward. It would pull the dependency graph from my API, and hash it to disk to start or resume a checkpoint. One by one, the tool would clone/pull the repository, apply the patch, run the build targets, create/update the branch, and push for review. Once complete, it would update the checkpoint and move onto the next repo in the list and repeat the process until all repositories in the graph had been processed.
This mechanism worked great! I’d kick things off, sit back, and relax. It would only be a day or so babysitting the script until that got old. At first, I tried using the built-in notification system and while it worked for when I was at my computer, I also wanted to be able to step away for a good portion of time. At the time, Twilio had a free low-volume solution that I was able to take advantage of. With a little more JavaScript and an existing SDK, I had an answer that would send me a text anytime my patch failed.
Kick back, relax, and wait
At this point, the only thing left to do was to sit back and wait. I brought my laptop down to the cafe with me so when I got a text, I could quickly hop on, resolve it, and resume the workflow. I’d grab a latte here or there, play a game or two of pool with friends and catch up with them about their projects. I’d usually fill them in on how the upgrade was going. The day the pipeline had finished was the day that the real work for this project had begun.
Stay tuned for my next post, where I cover the remaining 20% of this project and the challenges involved in coordinated a large-scale effort to merge and publish changes across an entire company. ~ Ciao bella!